library(ggplot2)
library(dplyr)
library(moderndive)
library(readr)Problem Set 06
Background
We will again use the hate crimes data we used in Problem Set 05. The FiveThirtyEight article about those data are in the Jan 23, 2017 “Higher Rates Of Hate Crimes Are Tied To Income Inequality.” This week, we will use these data to run regression models with a single categorical predictor (explanatory) variable and a single numeric predictor (explanatory) variable.
Setup
First load the necessary packages:
The following code uses the function read_csv() to read in the data and store the information in an object named hate_crimes.
Next, let’s explore the hate_crimes data set using the glimpse() function from the dplyr package:
glimpse(hate_crimes)Rows: 51
Columns: 9
$ state <chr> "New Mexico", "Maine", "New York", "Illinois", "Delaw…
$ median_house_inc <chr> "low", "low", "low", "low", "high", "high", "high", "…
$ share_pop_metro <dbl> 0.69, 0.54, 0.94, 0.90, 0.90, 1.00, 0.87, 0.86, 0.97,…
$ hs <dbl> 83, 90, 85, 86, 87, 85, 89, 90, 81, 91, 89, 89, 87, 8…
$ hate_crimes <dbl> 0.295, 0.616, 0.351, 0.195, 0.323, 0.095, 0.833, 0.67…
$ trump_support <chr> "low", "low", "low", "low", "low", "low", "low", "low…
$ unemployment <chr> "high", "low", "low", "high", "low", "high", "high", …
$ urbanization <chr> "low", "low", "high", "high", "high", "high", "high",…
$ income <dbl> 46686, 51710, 54310, 54916, 57522, 58633, 58875, 5906…You should also examine the data in the data viewer.
Each case/row in these data is a state in the US. This week we will consider the response variable income, which is the numeric variable of median income of households in each state.
We will use
- A categorical explanatory variable
urbanization: level of urbanization in a region - A numerical explanatory variable
share_pop_hs: the percentage of adults 25 and older with a high school degree
Income, Education and Urbanization
We will start by modeling the relationship between:
- \(y\): Median household income in 2016
- \(x_1\): numerical variable percent of adults 25 and older with a high-school degree, contained in the
hsvariable
- \(x_2\): categorical variable level of urbanization in a state:
low, orhigh, as contained in the variableurbanization
Exploratory Data Analysis
We will start by creating a scatterplot showing:
- Median household
incomeon the \(y\) axis - Percent of adults 25 or older with a high school degree on the \(x\) axis
- The points colored by the variable
urbanization - A line of best fit (regression line) for each level of the variable
urbanization(one for “low”, one for “high”)
R Code
ggplot(data = hate_crimes,
aes(y = income, x = hs, color = urbanization)) +
geom_point()+
geom_smooth(method = "lm", se = FALSE) +
labs(
x = "Percent of adults with high-school degree",
y = "Median household income in USD $",
title = "Income versus education in states with
differing levels of urbanization") +
theme_bw() +
theme(plot.title = element_text(hjust = 0.5))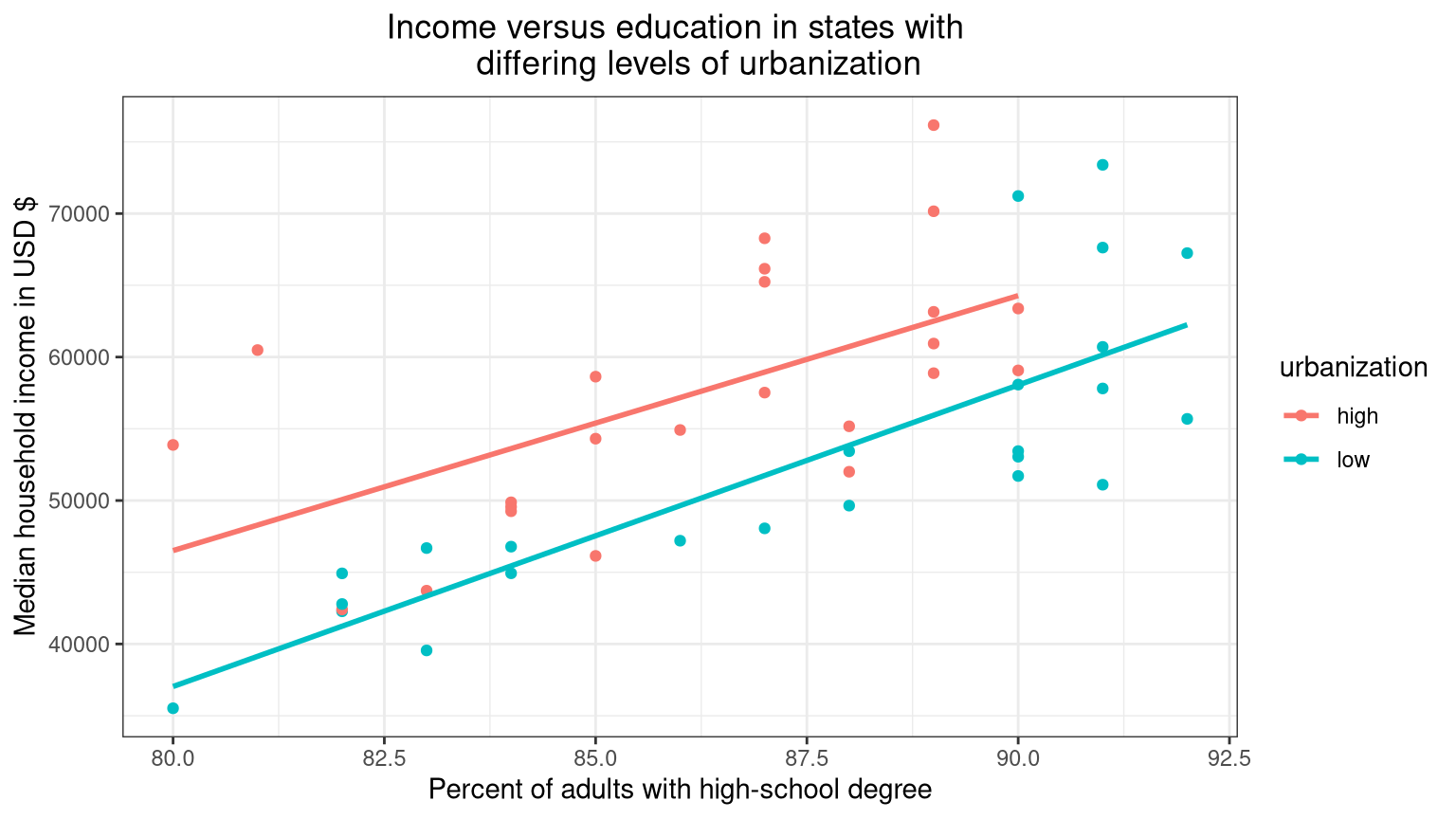
Independent Analysis

You will now use the tools you have learned, and a new data set to solve a conservation problem.
Wildlife biologists are interested in managing/protecting habitats for a declining species of vole, but are not sure about what habitats it prefers. Two things that biologists can easily control with management is percent cover of vegetation, and where habitat improvements occur (i.e. is it important to create/protect habitat in moist or dry sites, etc). To help inform habitat management of this vole species, the researchers in this study counted the number of voles at 56 random study sites. At each site, they measured percent cover of vegetation, and recorded whether a site had moist or dry soil.
The data are read into the object vole_trapping using the read_csv() function below.
The data contains the variables:
sitefor the id of each random study site (each case or row is a survey/trapping site)volesfor the vole count at each sitevegfor the percent cover of vegetation at each sitesoilidentifying a site as “moist” or “dry”
Turning in Your Work
You will need to make sure you commit and push all of your changes to the github education repository where you obtained the lab.
Tip
- Make sure you render a final copy with all your changes and work.
- Look at your final html file to make sure it contains the work you expect and is formatted properly.
Logging out of the Server
There are many statistics classes and students using the Server. To keep the server running as fast as possible, it is best to sign out when you are done. To do so, follow all the same steps for closing Quarto document:
Tip
- Save all your work.
- Click on the orange button in the far right corner of the screen to quit
R - Choose don’t save for the Workspace image
- When the browser refreshes, you can click on the sign out next to your name in the top right.
- You are signed out.
sessionInfo()R version 4.4.2 (2024-10-31)
Platform: x86_64-redhat-linux-gnu
Running under: Red Hat Enterprise Linux 9.5 (Plow)
Matrix products: default
BLAS/LAPACK: FlexiBLAS OPENBLAS-OPENMP; LAPACK version 3.9.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] readr_2.1.5 moderndive_0.7.0 dplyr_1.1.4 ggplot2_3.5.1
[5] scales_1.3.0 knitr_1.49
loaded via a namespace (and not attached):
[1] generics_0.1.3 tidyr_1.3.1 lattice_0.22-6
[4] stringi_1.8.4 hms_1.1.3 digest_0.6.37
[7] magrittr_2.0.3 evaluate_1.0.3 grid_4.4.2
[10] timechange_0.3.0 fastmap_1.2.0 Matrix_1.7-1
[13] operator.tools_1.6.3 jsonlite_1.8.9 backports_1.5.0
[16] mgcv_1.9-1 purrr_1.0.2 infer_1.0.7
[19] cli_3.6.3 rlang_1.1.4 crayon_1.5.3
[22] splines_4.4.2 bit64_4.5.2 munsell_0.5.1
[25] withr_3.0.2 yaml_2.3.10 tools_4.4.2
[28] parallel_4.4.2 tzdb_0.4.0 colorspace_2.1-1
[31] broom_1.0.7 vctrs_0.6.5 R6_2.5.1
[34] lifecycle_1.0.4 lubridate_1.9.4 snakecase_0.11.1
[37] stringr_1.5.1 htmlwidgets_1.6.4 bit_4.5.0.1
[40] vroom_1.6.5 janitor_2.2.1 pkgconfig_2.0.3
[43] pillar_1.10.1 gtable_0.3.6 glue_1.8.0
[46] xfun_0.50 tibble_3.2.1 tidyselect_1.2.1
[49] rstudioapi_0.17.1 farver_2.1.2 nlme_3.1-166
[52] htmltools_0.5.8.1 labeling_0.4.3 rmarkdown_2.29
[55] formula.tools_1.7.1 compiler_4.4.2